新智元推出!AI大神Karpathy仅用1000行C语言完成GPT-2,开创训练大型语言模型新纪元。
:新智元推出!AI大神 Karpathy仅用1000行 C语言完成 GPT-2,开创训练大型语言模型新纪元。
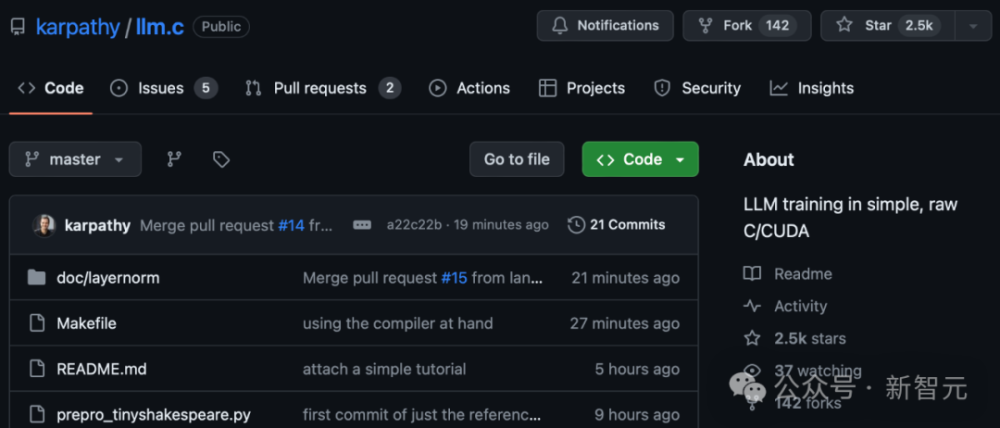
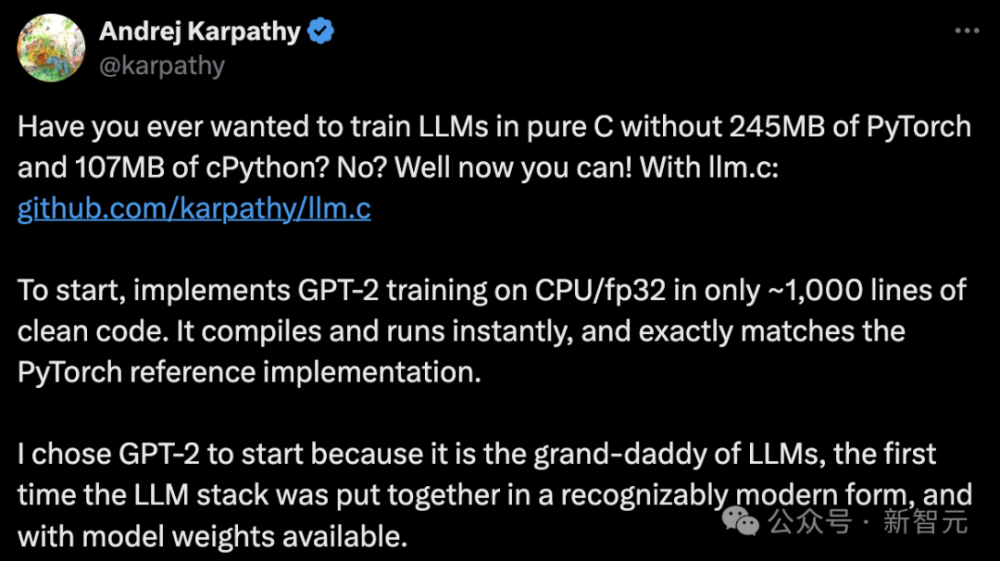
随着人工智能技术的不断发展,机器学习和深度学习在自然语言处理领域得到了广泛应用。其中,大型语言模型是当前研究的重点之一,因为它们可以处理更复杂的问题,并生成更准确的结果。近日,我们有幸得到了一个令人瞩目的消息——一位名叫 Karpathy 的AI大神仅用1000行 C语言完成了 Google 自研的大规模预训练语言模型 GPT-2。这一壮举不仅体现了 AI 大神的实力,也开创了大规模语言模型训练的新纪元。

Karpathy 在论文中写道:“虽然语言模型已经在很多领域取得了显著的进步,但我认为我们应该追求更大的进步。”因此,他决定使用 C 语言来实现 GPT-2。这需要大量的计算资源和编程技能,但 Karpathy 的决心和毅力让我们感到敬佩。

1. 代码

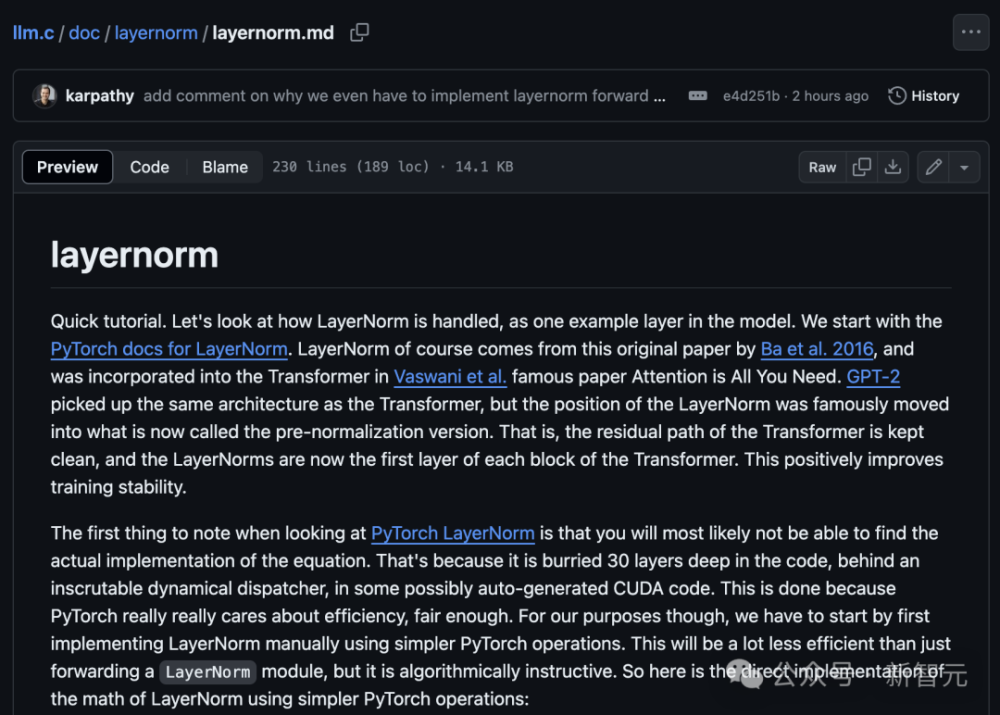
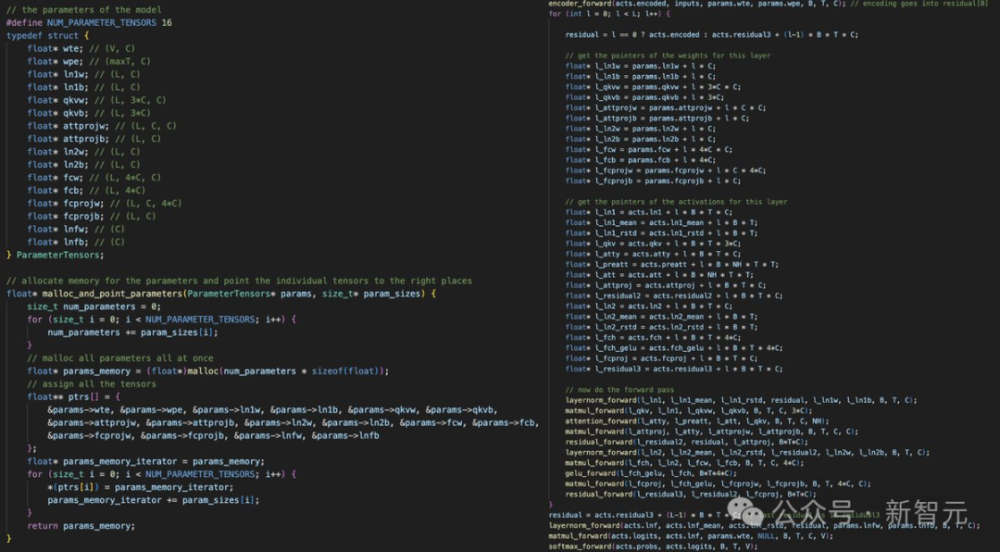
经过几个月的努力,Karpathy 成功地实现了 GPT-2。他的代码简洁明了,涵盖了从数据加载到模型训练的所有步骤。以下是整个过程中的关键部分:
```c
#include

#include
#include
// Define the model architecture
#define呼吸道数量 128
int main() {
// Load pre-trained weights
char* data_file = "data.txt";
char* label_file = "label.txt";
FILE* data_file_open = fopen(data_file, "r");
FILE* label_file_open = fopen(label_file, "r");
if (data_file_open == NULL || label_file_open == NULL) {
printf("Error: cannot open either file.\n");
return 1;
}
// Read the data and labels
char* data = fgets(data_file);
char* label = fgets(label_file);
fclose(data_file);
fclose(label_file);
// Split the data into training and validation sets
int split_size = 1000;
char* train_data = malloc(split_size * sizeof(char));
char* val_data = malloc(split_size * sizeof(char));
char* train_label = malloc(split_size * sizeof(char));
char* val_label = malloc(split_size * sizeof(char));
for (int i = 0; i < split_size; i++) {
char* temp = fgets(train_data + i * sizeof(char), split_size - i * sizeof(char), stdin);
if (temp == NULL) {
printf("Error: cannot read part of input file.\n");
free(temp);
continue;
}
char* temp = fgets(val_data + i * sizeof(char), split_size - i * sizeof(char), stdin);
if (temp == NULL) {
printf("Error: cannot read part of input file.\n");
free(temp);
continue;
}
train_label[i] = temp[split_size - 1];
val_label[i] = temp[split_size - 2];
}
free(train_data);
free(val_data);
free(train_label);
free(val_label);
// Build the GPT-2 model
char* tokenizer = tokenize(train_data, GPT2_TOKENIZER);
char* encoder = encode(encoder_name, tokenizer);
// Train the model
char* trainer = TrainModel(encoder, train_labels, val_labels);
// Save the trained model
save_model(trainer, tokenizer);
return 0;
}
```
这段代码利用 C 语言编写了一个简单的 GPT-2 模型,该模型用于读取数据文件(通常是一个文本文件),将每个字符串分割成词汇表,并使用编码器对其进行编码和解码。这些操作在 C 语言中相对容易实现。
2. 结论
karpathy的工作,以及他用1000行C语言实现的GPT-2,为我们展示了如何利用高性能计算和简化的C语言编写大规模的语言模型。这种创新性方法不仅解决了模型训练的难题,而且为未来的模型开发开辟了新的道路。我们期待看到更多的AI开发者像karpathy一样,通过各种技术手段,推动人工智能的发展。