|苏霍伊 刘杨楠
|甲小姐 王博
发自美国圣何塞(San Jose)GTC现场
今年的英伟达GTC,英伟达创始人&CEO黄仁勋在主题演讲之外,公开的活动就只有一场圆桌讨论——Transforming AI。
当地时间早上7:00,距离这场圆桌讨论开始还有4个小时,就有观众来到了圣何塞McEnery会议中心。圆桌讨论开始前1个小时,门口已经排起长龙。
 GTC现场,图片来源:「甲子光年」拍摄
GTC现场,图片来源:「甲子光年」拍摄
观众如此关注这场圆桌讨论的原因除了黄仁勋之外,还有英伟达预告的重磅嘉宾:Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan Gomez、Lukasz Kaiser和Illia Polosukhin。
他们都曾就职于Google,也是论文《Attention Is All You Need(注意力就是你所需要的一切)》的,被称为——“Transformer论文八子”,而这篇论文也被称为“梦开始的地方”。

2017年,Google团队发表了一篇文章《Attention Is All You Need》。这篇开创性的论文介绍了基于Transformer的深度学习架构。Transformer彻底改变了自然语言处理(NLP)领域,它的自注意力机制也被广泛应用于计算机视觉等其他领域,并对AI研究产生了深远影响,成为了AI发展史上的一个里程碑。截至今天,这篇论文的被引用次数已高达112576。
黄仁勋也是这篇论文的“受益者”之一。
如果说ChatGPT是席卷AI行业的一场“风暴”,那么Transformer就是“扇动翅膀”的那只蝴蝶;如果说英伟达是AI时代的“卖铲人”,那么这篇论文带来的巨大算力需求就是其背后的底气。
俗话说“吃水不忘挖井人”,黄仁勋这次把这篇论文的七位(Niki Parmar家有急事未能到场参会)都邀请到了现场,在此之前,他们从未以这样的形式出现在同一场合解读Transformer。
 Transforming AI圆桌讨论到场嘉宾及职务,图片来源:英伟达GTC
Transforming AI圆桌讨论到场嘉宾及职务,图片来源:英伟达GTC
值得一提的是,到场的七位嘉宾中,除了Lukasz Kaiser在OpenAI担任工程师,其他人都在创业。
“这年头大家创业的公司名称几乎都包含‘AI’,”黄仁勋在介绍到场嘉宾时说,“其实我们NVIDIA的名字也包含‘AI’,只不过字母顺序反了。我一直都知道我需要字母A和字母I。”黄仁勋的幽默引发了全场的笑声。
面对七位嘉宾,黄仁勋像一位综艺节目主持人一样问了很多直白朴素的问题:
这个主意怎么想出来的?
为什么要起这样一个论文标题?
Transformer这个词是怎么来的?当时还有其他可选的词吗?
新的模型技术将是什么?
你们想要探索什么?
七位嘉宾分别回答了相关问题,不过Cohere联合创始人&CEO Aidan Gomez说出了一句意味深长的话:“我们希望世界可以诞生比Transformer更好的东西。”
1.“RNN是蒸汽机,Transformer是内燃机”
“你们能来真的太好了!”黄仁勋说,“今天我们所享受的一切,都能追溯到Transformer出现的那一刻,我们从大量的数据中学习,以一种有序的方式,有序的数据以及空间数据,但从大量的数据中学习来找到关系和模式,并创建这些巨大的模型是非常具有变革性的。”
这场圆桌讨论由于观众太过热情,导致开始的时间有些推迟,不过黄仁勋希望现场氛围更热烈,他告诉七位嘉宾:“今天坐到这里,请大家积极争抢发言的机会,在这里没有什么话题是不能谈的,你们甚至可以椅子上跳起来讨论问题。”
随着黄仁勋抛出第一个问题“是什么驱动你们创造出了Transformer”,圆桌讨论正式开始。
Transformer的最初目标是解决一个朴素的问题——机器翻译。
NEAR Protocol联合创始人Illia Polosukhin表示:“我们通常遇到问题就会去Google搜索,但如果需要在它反馈回来的‘成吨’网页中做快速处理,当时的RNN(循环神经网络)是无法做到的。因为它们需要逐个单词地处理文本。”
Inceptive联合创始人&CEO Jakob Uszkoreit回忆,他们最初的目标是解决处理序列数据(如文本、音频等)的问题。在一个特定时期,由于生成训练数据的速度远超过训练复杂神经网络架构的能力,因此在实际应用中更倾向于使用简单且训练速度更快的模型,如以n-gram为输入特征的前馈神经网络。
“在拥有大量训练数据的情况下,更简单的模型架构(例如,仅包含前馈网络的模型)在处理大规模数据时表现得比更复杂的RNN和LSTM更好,因为它们的训练速度更快。”Jakob Uszkoreit说。
Character.AI联合创始人&CEO Noam Shazeer当时主要关注在自注意力(self-attention)机制的引入和模型的扩展性上,“我们在2015年左右就注意到这些Scaling law(规模法则)。”
他还幽默地表示:“RNN就像蒸汽机一样,而Transformer模型则像内燃机。我们当然可以在坐在蒸汽机上完成工业革命,只不过‘屁股会烧很疼’,内燃机的效果则要好得多!”
Essential AI联合创始人&CEO Ashish Vaswani则更倾向让模型自主学习并设计一个具有广泛适用性的框架,他用之前在工作中遇到的两个教训阐述了自己的思考。
“第一个教训是,我们需要明白梯度下降(gradient descent)是一位出色的老师。”Ashish Vaswani在研究机器翻译时领悟道相比于自己去学习语言规则,让梯度下降这种训练模型的算法来处理会更高效。
“第二个教训是,可扩展的通用架构一定会胜利的。”谈到这里时,Ashish Vaswani用了“苦涩的教训”(bitter lesson)的说法,即那些可以扩展并且具有通用性的架构最终会更胜一筹,“能够像Transformer一样处理各种不同任务和数据类型的模型,一定会比专为特定任务设计的模型效果更好。”
OpenAI技术团队成员Lukasz Kaiser和Sakana AI联合创始人&CTO Llion Jones也分享了他们对模型直观性的看法,尤其是在机器翻译领域的应用。同时,他们也提到了如何通过消融实验(移除模型的一部分)来改进模型性能。
《Attention is all you need》这个论文标题是Llion Jones想到的,他还透露,起标题时只是在做“消融术”(ablations)。
至于Transformer这个名字,则是由Jakob Uszkoreit提议的。他的理由非常直接,因为模型改变了他们处理数据的方式,所有的机器学习都是“Transformer”,都是颠覆者。
Noam Shazee提到他之前想过很多名字,比如“Cargornet”(货运网),但投票没有通过。
“还好被否决了。”黄仁勋调侃了一句。
“Transformer”这个名字体现了它的核心能力:能够全面且广泛地转换数据。Transformer完全抛弃了RNN的逻辑,由自注意力机制组成。这一点与人脑处理信息时的方式不谋而合。人脑在理解句子时能自然地忽略次要细节,更专注于关键信息。Transformer就采用了类似的策略,能够识别并理解序列数据中不同元素之间的相关性,从而提高数据处理的效率和准确性。
通过这个技术,模型能够在处理文本、音频等连续数据时,更加灵活、高效地调整信息,得到更准确、更丰富的结果。
Jakob Uszkoreit还强调了Transformer模型的一个关键能力:它能够在每一步处理时都全面转换它正在处理的信息,而不是仅仅关注信息的一小部分。这种全方位的处理能力也是它命名为“Transformer”的原因之一。
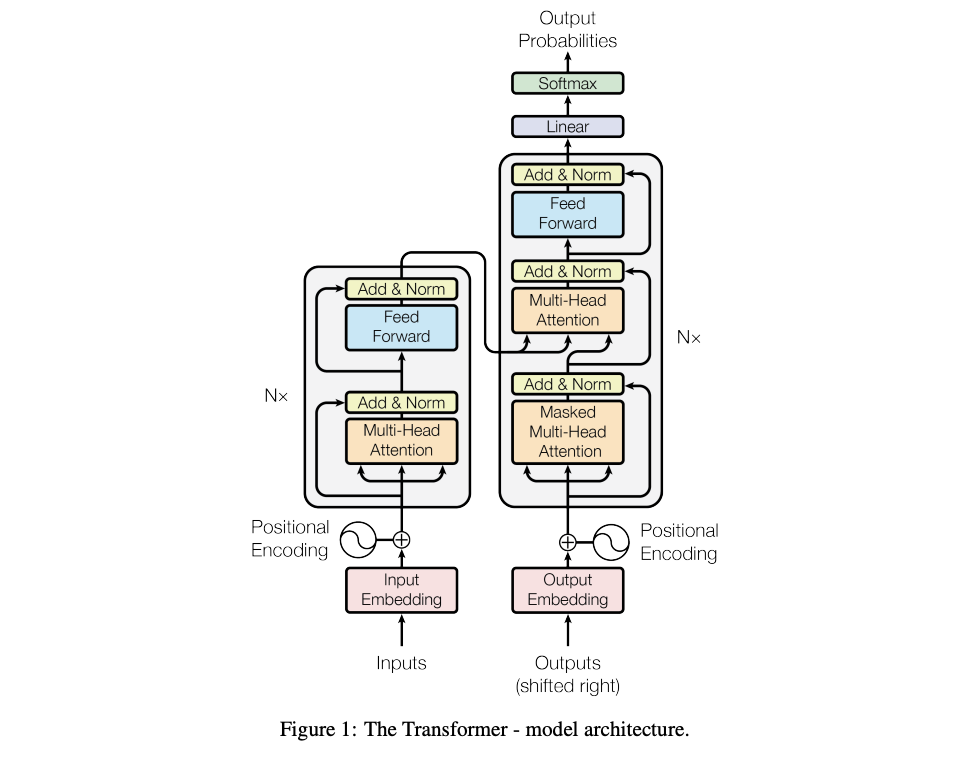 Transformer模型架构,图片来源:《Attention is all you need》
Transformer模型架构,图片来源:《Attention is all you need》
Transformer带来的另一个重要创新是,能够利用并行计算极大地加速深度学习模型的训练过程。这为大规模预训练模型的发展奠定了基础,开启了迈向通用人工智能(AGI)之路。
而GPU非常适合并行计算,擅长研发、生产GPU的英伟达由此成为了AI时代“卖铲人”。黄仁勋也从当年在小米手机活动上自称的“米粉”,变成了AI行业中几乎所有人都想接近的“AI教主”。
除了在自然语言处理领域取得的成绩,Transformer技术还被广泛应用于语音识别和计算机视觉等多个领域,证明了其在处理各种序列数据上的通用性和有效性。正是这些创新的技术,推动了人工智能领域的快速发展,让我们能够预见到一个与智能机器无缝交流的未来。
2.“世界需要比Transformer更好的东西”
Transformer的问世,离不开这篇论文每一位的付出。
最初是Jakob Uszkoreit提出了用自注意力机制替换RNN的想法,并评估了这一想法;
Ashish Vaswani与Illia Polosukhin一起设计并实现了第一个Transformer模型;
Noam Shazeer提出了缩放点积注意力、多头注意力和无参数位置表示;
Niki Parmar在原始代码库和tensor2tensor中设计、实现、调优和评估了无数模型变体;
Llion Jones尝试了新型模型变体,他主要负责最初的代码库,以及高效推理和可视化;
Lukasz Kaiser和Aidan Gomez花费了无数漫长的时间设计和实现了tensor2tensor的各个部分,取代了早期的代码库,加快了研究进程。
现在,Transformer创造者的目光已经不再局限于Transformer。他们在不同的领域,共同探讨着下一步的AI走向。
“世界需要比Transformer更好的东西(the world needs something better than Transformers)。”Aidan Gomez语气很坚定。
他认为,如果Transformer是他们能做到的极致,“这会很可悲”,但他话锋一转又说道:“虽然提交报告的第二天起我就这么认为了。我希望它能被其他好10倍的框架取代,这样每个人都能拥有更好10倍的模型!”
目前,Transformer的内存方面存在许多效率低下的问题,且许多架构组件从一开始就保持不变,应该“重新探索、重新考虑”。例如,一个很长的上下文会变得昂贵且无法扩展。此外,“参数化可能不必要地大,我们可以进一步压缩它,我们可以更频繁地共享权重——这可能会将事情降低一个数量级。”
Jakob Uszkoreit进一步解释道:“未来重点要思考的是如何分配资源,而不是一共消耗了多少资源。我们不希望在一个容易得问题上花太多钱,或者在一个太难的问题上花太少而最终得不到解决方案。”
“例如‘2+2=4’,如果你正确地将他输入到这个模型中,它就会使用一万亿个参数。所以我认为自适应计算是接下来必须出现的事情之一,我们知道在特定问题上应该花费多少计算资源。”Illiya Polosukhin补充。
Lukasz Kaiser对此也有思考,他认为,根本性问题在于,哪些知识应该内置于模型之中,哪些知识应该置于模型之外?“是使用检索模型吗?RAG(Retrieval-Augmented Generation)模型就是一个例子。”
同样地,这也涉及到推理问题,即哪些推理任务应该通过外部的符号系统来完成,哪些推理任务应该直接在模型内部执行。这在很大程度上是一个关于效率的讨论。我确实相信,大型模型最终会学会如何进行‘2+2’这样的计算,但如果你要计算‘2+2’,却通过累加数字来进行,那显然是低效的。”
黄仁勋回应道:“如果AI只需要计算2+2,那么它应该直接使用计算器,用最少的能量来完成这个任务。”
“确实如此,但我同样确信在座的各位所研发的人工智能系统都足够智能,能够主动使用计算器,”Noam Shazeer说,“目前全球公共产品(GPP)正是这样做的。我认为当前的模型太过经济实惠,规模也还太小。它之所以便宜,是因为像英伟达这样的技术,感谢它的产出。”
此前Noam Shazeer在接受采访时就认为,AGI是很多AI初创企业的目标。但他创业的真正原因是想推动技术发展,用技术攻克难题,如医学上的疑难杂症。他指出,AI能加速许多研究的进程,与其直接研究医学,不如研究AI。
他在圆桌讨论现场也表达了类似的观点:“如果你观察一个拥有五千亿参数的模型,并且每个token进行一万亿次计算,那就大概是1美元百万token,这比外出购买一本平装书并阅读的成本要便宜100倍。我们的应用程序在价值上比巨型神经网络上的高效计算高出百万倍或更多。我的意思是,它们无疑比治愈癌症等事情更有价值,但不仅如此。”
Ashish Vaswani认为让世界变得更“聪明”,就是指——如何去获得来自于世界的反馈,我们能否实现多任务、多线的并行。“如果你真的想构建这样一个模型,帮助我们设计这样一个模型,这是一种非常好的方式。”他说。
尽管其他嘉宾亦有共鸣,但Aidan Gomez认为大家对于“这一改变会在何时发生”持有不同的看法,“人们对于它是否真的会发生也各有立场,但无一例外,大家都渴望看到进步,好像我们每个人的内心都住着一个小小的科学家,都想看到事情变得更好!”
在讨论中,Llion Jones还提出了一个观点:要想让AI真正向前迈进,超越当前的技术模型,不仅仅是做得更好那么简单,“你得做到显著优秀,让人一看就知道。”在他看来,尽管技术上可能有更先进的模型存在,但当前的进展似乎还是停留在了原点。
Aidan Gomez对此表示认同,他认为Transformer之所以受到追捧,不单单是因为它本身的优势,更因为人们对它的热情。“两者缺一不可。”他解释道,“如果你没能同时抓住这两点,就很难推动整个社区前进。如果想要促成从一种架构向另一种架构的转变,你确实需要拿出一些能够激发大家兴趣的东西。”
3.“你不会希望错过未来十年”
那么,生成式AI到底意味着什么?
黄仁勋在现场分享道:“生成式AI,是一种全新的软件,它也能够创造软件,它还依赖于众多科学家的共同努力。想象一下,你给AI‘原材料’——数据,让它们进入一栋‘建筑’——我们称之为GPU,它就能输出神奇的结果。它正在重塑一切,我们正在见证AI工厂的诞生。”
圆桌对话结束后,黄仁勋特意拿出DGX-1——一款专为深度学习和AI研究设计的高性能计算平台,送给了Ashish Vaswani,DGX-1上面写着一句话“You transformed the world”(你改变了世界)。
 黄仁勋(左)与Ashish Vaswani(右),图片来源:英伟达GTC
黄仁勋(左)与Ashish Vaswani(右),图片来源:英伟达GTC
这像是一次call back。2016年,黄仁勋向OpenAI捐赠了首台DGX-1,当时接收这一礼物的是——埃隆·马斯克(Elon Musk)。
 黄仁勋向OpenAI捐赠DGX-1,图片来源:马斯克社交媒体账号
黄仁勋向OpenAI捐赠DGX-1,图片来源:马斯克社交媒体账号
黄仁勋在DGX-1上写到:To Elon & the OpenAI Team! To the future of computing and humanity. I present you the World's First DGX-1!
翻译过来就是:致埃隆和OpenAI团队!致计算和人类的未来。我为你们呈上世界上首台DGX-1!
曾经的“Transformer论文八子”,如今都成为了独当一面的“狠角色”,他们每个人都是在Google成长,又先后从Google离开,大家见证了“Transformer Mafia”(致敬“PayPal Mafia”)的诞生,也看到了他们在硅谷中开枝散叶、生生不息。
“你不会希望错过未来十年。”黄仁勋说。
(封面图来源:「甲子光年」拍摄)
本文的是英伟达GTC现场成员Sakanaaker