
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
Transformer中唯一去了OpenAI的那位,公开承认了:
他参与了Q*项目,是这项新技术的发明者之一。
这几天除了英伟达老黄组局把Transformer聚齐,他们中的几位还接受了连线杂志的采访,期间出了这么一个小插曲。
当记者试图询问Lukasz Kaiser更多关于Q*的问题时时,OpenAI的公关人员几乎跳过桌子去捂他的嘴。

结合奥特曼在接受采访时,毫不迟疑地拒绝了相关提问,“我们还没准备好谈论这个话题”。
神秘Q*,成了OpenAI当前最需要保守的秘密之一。

不过对于Transformer背后的开发内幕,以及谷歌究竟为什么没能在得到这项技术之后抢先推出轰动世界的AI产品,们透露了不少:
- 1 Noam Shazeer(现Character.AI创始人)才是贡献最大的
- 2 谷歌早在2012年尝试开发生成式AI搜索
- 3 2017年他们就建议训练万亿参数大模型,但未被高层采纳
总之,信息量比几位在老黄的圆桌论坛上商业互吹要高得多。
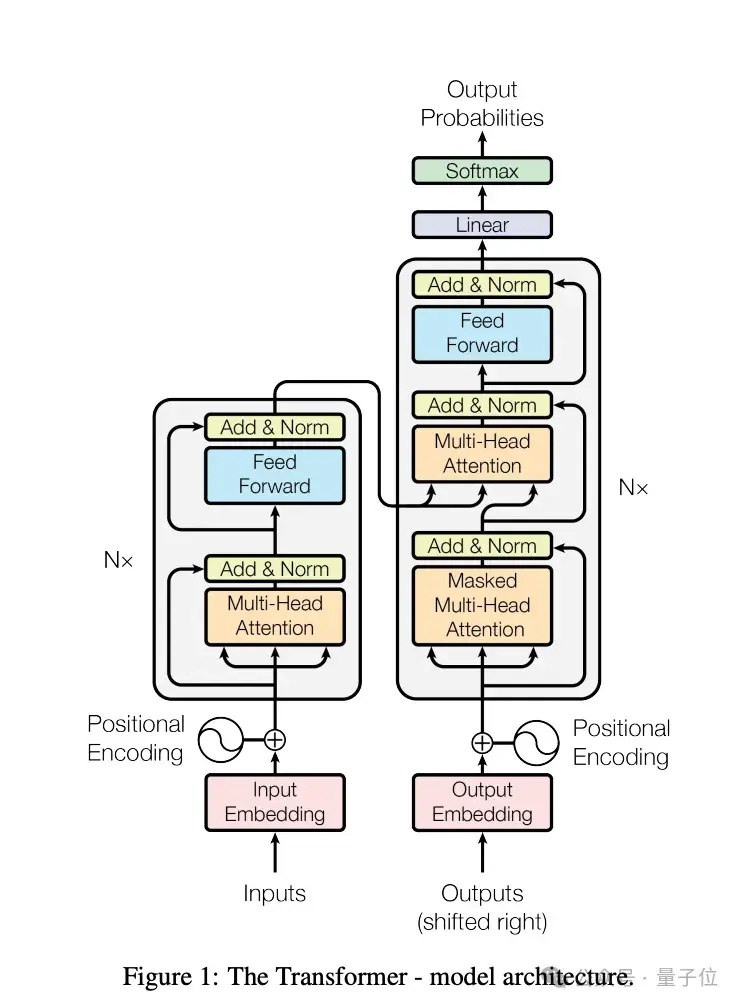
《Attention is all you need》发表于2017年,到现在被引次数已超过11万。

它不仅是当今ChatGPT为代表的大模型技术起源之一,其中介绍的Transformer架构和注意力机制也被用在了Sora、AlphaFold等众多改变世界的AI技术之中,是当之无愧的传奇。
为什么是谷歌能搞出这等成果?谷歌又为什么在后来的大模型竞争中落后?
整个故事还要从2012年说起。
01 谷歌害怕Siri抢饭碗
2011年底,苹果正式推出Siri,试图在对话中提供对问题的答案。
谷歌高层如临大敌,认为Siri可能会抢走他们的搜索流量。
2012年,一个团队致力于开发新功能,期望能在搜索页面上直接回答用户的问题,而不用点击链接跳转到其他网站。
最终这项努力催生出了Transformer架构,能有效在数据和算力上扩展,导致了整个AI领域重大突破。
Jokob Uszkoreit(现AI生物技术公司Inceptive联合创始人)就是在这个时候放弃攻读博士学位加入了这个团队,成为Transformer最初的起点。
他来自德国,硕士毕业于柏林工业大学,父亲Hans Uszkoreit是著名计算语言学家、欧洲科学院院士。
在Uszkoreit(后简称乌兹哥)现在看来,谷歌高层当时对Siri的恐慌是没必要的,Siri从未真正威胁到过谷歌的业务,但他很高兴能有机会深入研究AI和对话系统。
2012年也是AlexNet在计算机视觉大获成功、神经网络复兴的时候,谷歌疯狂地安排员工尝试类似的技术,希望能开发出自动补全电子邮件的功能,或相对简单的客户服务聊天机器人。
当时最被认可的方案是长短期记忆网络LSTM,但这项技术只能按照顺序处理句子,无法有效利用文章后面可能出现的线索。
直到2014年左右才有了新进展,乌兹哥开始尝试现在被称为“自注意力”的方法。
02 注意力机制诞生
乌兹哥认为自注意力模型可能比循环神经网络更快、更有效,处理信息的方式也非常适合擅长并行处理的GPU。
但当时,包括他的学术大牛父亲在内,许多人都不看好,认为抛弃了循环神经网络就是一种异端。
乌兹哥花了一些力气说服几位同事一起试验新想法,并于2016年发表了一篇相关论文。

在这项研究中只使用了极小的文本训练(SNLI数据集,包含57万个人类写的英语句子)。
乌兹哥希望进一步推进他们的研究,但他的合都不感兴趣再继续了。
其他研究人员就像在答题闯关中刚答对了一道题就带着微薄的奖金离开,但乌兹哥坚持认为自注意力机制可以发挥更大的作用,开始在公司里到处找人安利他的想法。
2016年的一天,他终于遇到志同道合的人Illia Polosukhin(现区块链公司NEAR Protocol创始人)。
03 集齐8位圆桌骑士
Polosukhin(后简称菠萝哥)当时已在谷歌工作三年,被分配到为搜索问题直接提供答案的团队。
菠萝哥的进展不顺利,因为从用户体验出发,需要在几毫秒内对问题产生回应,当时还没有这么高性能的解决方案。
乌兹哥与菠萝哥共进午餐的时候听说这事,毫不犹豫的安利起他的自注意力机制。
菠萝哥曾透露,他后来觉得A自注意力就像科幻小说《你一生的故事》以及改编电影《降临》里外星人“七肢桶”的语言,没有先后顺序,而是像几何图案一样排列。

总之,菠萝哥后来不仅同意尝试,还拉来了第三位成员Ashish Vaswani合作(先后创办了Adept AI和Essential AI)。
Vaswani(后简称瓦斯哥)来自印度,博士毕业于南加州大学后加入谷歌大脑,相信神经网络将促进人类整体的理解能力。

三位研究人员共同起草了Transformer的设计文档,他们从第一天开始就选择了同样代表“变形金刚”的这个名字,因为“系统会改变接收到的信息”,也因为菠萝哥小时候喜欢玩变形金刚玩具。
不过菠萝哥没过多久就从谷歌离开去创业了,同时,其他成员陆续加入这个小队伍。
2017年初,第四位成员Niki Parmar(后简称帕姐)加入,他与瓦斯哥同样来自印度、也都毕业于南加大,后来两人也成了创业伙伴。
后面几位成员的加入多少都带点戏剧性。
第五位Llion Jones(后简称囧哥)来自英国,2009年硕士毕业于伯明翰大学,但有好几个月找不到工作靠救济金工作。2012年他先加入Youtube团队,后进入谷歌研究院。
他是团队中最晚从谷歌离职的,去年在日本成立了Sakana AI。
囧哥是从另一位同事Mat Kelcey(他就出现一次,不用简称了)那里听说Transformer的,不过Kelcey自己当时并不看好这个项目。
Kelcey信奉贝叶斯,他的头像是AI预测他是技术宅的概率为60%。后来他认为没加入Transformer团队这是他一生中最大的预测失误。
话说回来,第六位Aidan Gomaz(后简称割麦子,现AI公司Cohere创始人)是最年轻的,他在多伦多大学读大三时加入Hinton的实验室,主动给谷歌里各种写过有意思论文的人发邮件申请合作。
第七位Lukasz Kaiser(后简称凯哥,现OpenAI研究员)邀请了割麦子参与实习。直到几个月后,割麦子才知道这实习本来是针对博士生的,而不是他一个本科生。
凯哥来自波兰,本来做的是理论计算机工作,后来发现自注意力对他们当时正在解决的问题(可分布式计算的大型自回归模型)是一种有前途且更激进的方案,两人就加入了Transformer团队。
六人(菠萝哥已经创业去了)聚到一起后,团队开始把试验方向定在机器翻译,使用BLEU基准测试来把模型翻译结果与人工翻译做比较。
早期Transformer原型表现不错,但只是与LSTM方案差不多,并没有更好。
此时,第八位关键成员Noam Shazeer(后简称沙哥)出场了,他毕业于杜克大学,2000年加入谷歌,当时全公司只有200人左右,
后来他成为谷歌内部的传奇人物,参与了谷歌搜索的拼写纠正功能,也负责过早期广告系统,2021年离开谷歌后创办了Character.AI。

据沙哥回忆,当时他正在办公楼走廊里走,经过凯哥的工位时听到激烈的对话:瓦斯哥正在谈论如何使用自注意力,而帕姐对此很兴奋。
沙哥觉得这是一群有趣的聪明人在做有前途的工作,最终被凯哥说服加入。
至此,8位传奇人物终于全部登场。
04 冲刺NIPS
沙哥的加入至关重要,他用自己的想法重新编写了整个代码,把整个系统提升到了一个新的水平。
团队一下充满动力,开始拼命卷自己,想在2017年NIPS(后改名NeurIPS)截止的5月19日之前完成。
Deadline前的最后两周,他们大部分时间都在咖啡机附近的办公室,很少睡觉。
割麦子作为实习生不断地疯狂调试,试验各种技巧和网络模块的排列组合。
最终在沙哥的帮助下,人们现在所知道的Transformer架构诞生了,相比试验中的其他方案显得非常“极简主义”。他们这样评价:
Noam(沙哥)是一个巫师。
沙哥厉害,但是沙哥并不自知。看到论文草稿的时候,他发现自己是一作还很惊讶。
讨论一番后,最终他们决定打破学术界一作二作通讯作的规则,随机排序,并给每个人名字后都打上星号,脚注标明都是平等贡献者。
在给论文取名字的阶段,来自英国的囧哥提议借用披头士乐队的歌曲《All You Need Is Love》,改成《Attention is all you need》,其他人也同意了。

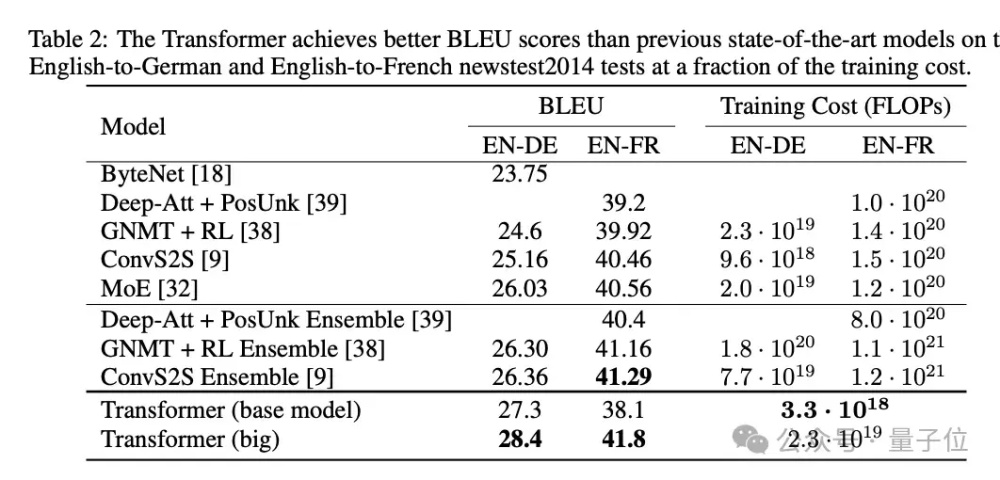
他们训练了基础和大杯两个模型,其中65M基础版就击败了所有同级竞争对手,213M大杯版甚至破了BLEU测试的记录,同时计算效率也更高。
直到截止日期最后几分钟,他们还在继续收集实验结果,英法翻译的数据是最后5分钟出来的,论文在最后两分钟提交。
当时学术会议审稿人的反应不一,一个评价积极,一个评价非常积极,第三个评价是只是“还算ok”。
到了12月会议正式线下举办的时候,这篇论文引起了轰动。4小时的会议上挤满了想要了解更多的科学家。
参会的几位一直聊到嗓子嘶哑,最后场地闭馆时仍然人头攒动,最后被保安清场。
从整个Transformer诞生历程来看,谷歌当年的开放包容的文化是必不可少的:
这八个人聚在一起,是靠走廊里的偶遇和午餐时聊天。
05 OpenAI摘桃子
回到论文撰写过程中的某一天,瓦斯哥累得瘫倒在办公室的沙发上,盯着窗帘看出了幻觉,觉得布料上的图案就像突触和神经元。
那天他突然意识到,他们正在做的事情将超越机器翻译。
最终就像人脑一样,将所有语音、视觉等所有模态统一在一个架构下。
沙哥则在应用方向上有惊人的远见,论文发表前后就给谷歌高管去了一封信。
他提议公司放弃整个搜索索引,并用Transformer架构训练一个巨大的神经网络替代,基本上是在建议谷歌改变整个信息组织的方式。
当时团队里凯哥都还认为这个想法很荒谬。但如今看来,谷歌正在朝这个方向努力,只是个时间问题了。
乌兹哥后来复盘,在2019年或者2020年谷歌就有机会推出GPT-3,甚至是GPT-3.5等级的模型,还发出灵魂提问:
我们看到了可能性,但为什么不采取行动呢?
结果却是对手OpenAI的首席科学家Ilya Sutskever在论文发表当天就意识到“它给了我们想要的一切”,并建议同事Alec Radford开始动手研究。
Radford先开发了GPT的原型,然后OpenAI调动更多人从机器人、DOTA游戏等项目转型,参与进来开发了GPT-1、GPT-2……这就是另外一个故事了。
打造一种能同时在数据和算力上扩展的模型,是Transformer架构的出发点,也是其成功的关键。
但少了顶层设计和推动,谷歌也就只能止步于此,单靠员工自发已经无法组织起满足Scaling Law发展下去需要的人力物力财力。
OpenAI的组织形态既有自下而上的灵活、又有自上而下的专注,能在这条路上走的更远几乎是不可避免的。
OpenAI CEO奥特曼曾评价,谷歌高层当时似乎没人认识到Transformer真正意味着什么。

如今8位也陆陆续续从谷歌离职,既然公司迟迟不肯用Transformer搞事情,那就自己去搞。
除了最早离开的菠萝哥的区块链公司之外,其它成员的的去向都和Transformer相关。
2019年,实习生割麦子毕业没多久,就先带头创办Cohere,为企业提供大模型解决方案,目前估值22亿美元。
2021年开始,成员集中出走。
瓦斯哥和帕姐先后携手创办Adept AI(估值10亿美元)、Essential AI(融资800万美元),都是自动化工作流程方向。
沙哥创办AI角色扮演聊天平台Character.AI,现在估值约50亿美元,用户活跃度和留存率比OpenAI都高。
乌兹哥回到德国创办的生物AI技术公司Inceptive,估值3亿美元。甚至乌兹哥透露,他的计算语言学家老父亲也在筹办一家新的AI公司,同样基于Transformer。
只有凯哥没有创业,2021年他加入了OpenAI,后来参与了GPT-4,以及Q*项目。
最后离开的是囧哥,23年他到日本创办的Sakana AI估值2亿美元,最新成果是用擅长不同领域的大模型融合,结合进化算法,搞出更强的模型。
……
许多谷歌老员工批评谷歌慢慢从一个以创新为中心的游乐场,转变为一个注重利润的官僚机构。
甚至在2020年,谷歌Meena聊天机器人发布后,沙哥又发了一封内部信“Meena吞噬世界”,其中的关键结论是:
语言模型将以各种方式越来越多地融入我们的生活,并且将在全球算力中占主导地位。
这太有前瞻性了,几乎准确预言了后来ChatGPT时代发生的事,也就是现在进行时。
但当时谷歌高层仍旧不为所动,关键决策者忽略甚至嘲笑他。
谷歌曾拥有整个AI王国的所有钥匙,却弄丢了钥匙链。
参考链接:
[1]https://www.wired.com/story/eight-google-employees-invented-modern-ai-transformers-paper/
[2]https://www.youtube.com/watch?v=zBK2CPka5jo
[3]https://www.semianalysis.com/p/google-gemini-eats-the-world-gemini
本文讲述了OpenAI团队的8位重要成员如何在Kairolles机制造成了Transformer架构,这是一种能同时在数据和算力上扩展的大规模预训练模型,被誉为“机器翻译之父”。这些参与者最初都认为Transformer是异端,但他们后来逐渐认同了这种架构的价值,将其用于Google搜索引擎、文本分类和自然语言理解等领域,并取得了显著的成就。然而,当谷歌的高层领导层忽视甚至嘲笑这个项目时,这群人才最终决定摆脱封闭的文化,自主研究Transformer,并将其应用于更大的场景。这一事件展示了谷歌从一个专注于创新和自由探索的公司转变为注重利润和规范的机构的过程。最后,Transformer在当前和未来都有着广泛的应用前景。












