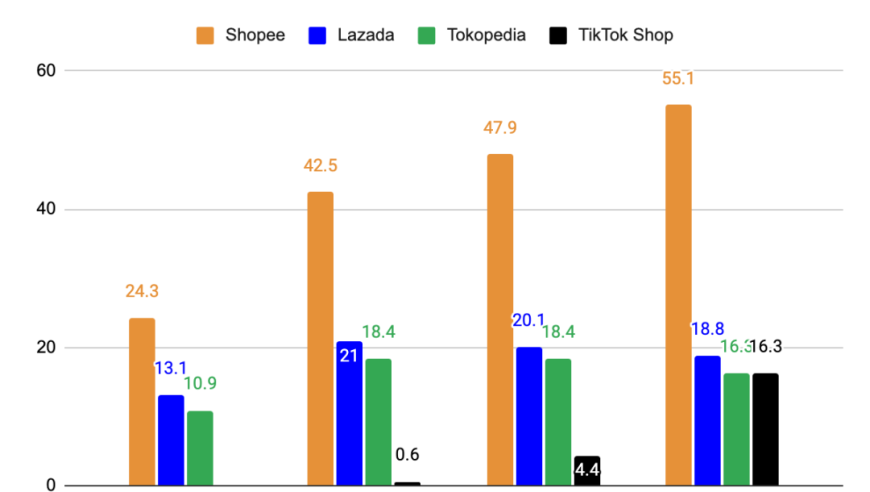
如果要说哪家公司是目前全球最炙手可热的公司,相信很多人第一时间的答案一定是老黄的英伟达。
在前不久公布的2023年度财报当中,英伟达营收达到了609.22亿美元,净利润297.6亿美元,同比分别增长126%和581%。
横向比较一下,英特尔2023年营收542亿美元,净利润16.89亿美元,同比分别下降14%和78.9%,AMD营收226.8亿美元,净利润8.54亿美元,同比分别下降3.9%和35.3%,英伟达在同类型公司中可谓鹤立鸡群。
因为AI革命的发生,英伟达的芯片在过去一年一直处于供不应求的状态,以至于它的毛利率达到了恐怖的72.7%,超过了茅台。
那么作为一家高科技企业,英伟达接下来是会挤牙膏收割毛利,还是进一步创新推高AI算力呢?就在今天早上的GTC2024上,黄仁勋给了我们答案。
01
想要快,就要大!
想要芯片速度更快,该怎么办?
那就造的大一些!这是黄仁勋今早在GTC 2024上给出的答案。
这个大芯片,是目前英伟达,或者说这个地球上最快的AI计算芯片,它就是全新一代的BlackWell GPU芯片。

左侧为BlackWell,右侧为Hopper
与上一代的Hopper相比,新一代的芯片在面积上的确大出了不少。老黄解释道,这是因为一块完整的BlackWell芯片,其实是由两块同架构的小芯片构成。

两块小芯片合成一个完整的BlackWell
因为制程从之前的台积电4N工艺升级到了现在的4NP工艺,所以即使单个小芯片的晶体管也比之前提升了200亿个,当两个小芯片合在一起后,一块完整的BlackWell芯片的晶体管数量达到了惊人的2080亿!要知道,上一代的Hopper规格只是800亿。

完整的BlackWell拥有2080亿个晶体管
在显存方面,新芯片依然采用了HBM3E规格的显存,但是容量从141GB提升到了现在192GB,带宽从4.8TB/S提升到了8TB/S。
除了晶体管带来的计算能力提升,在架构上,英伟达对于FP4这个精度的计算也做了一些优化,在这个精度上,计算能力相比上代提升了5倍,其它的精度上,BlackWell的提升大约在2.5倍左右。这就像给一台发动机在增大的排量的同时,还给内部进行了一些优化,双管齐下,跑的更快了。

FP4精度不高,但响应快,因此一般都用在大模型的推理当中,优化过后,使用新芯片进行推理的速度提升了30倍。
也就是说,如果把目前的ChatGPT中的GPU都换成BlackWell,那么我们得到回答的速度将会有着至少十几倍的提升。抛开专门的FP4优化,在正常的大模型训练下,采用新芯片的GB200计算卡,要比老款H100快上2.5倍到4倍。
演讲中,老黄并没有提到配备一个GPU芯片的B200或者B100,只拿出了配备了2块GPU+1块CPU的GB200。其中的CPU依然是上一代ARM架构的Grace,只是GPU有了升级。

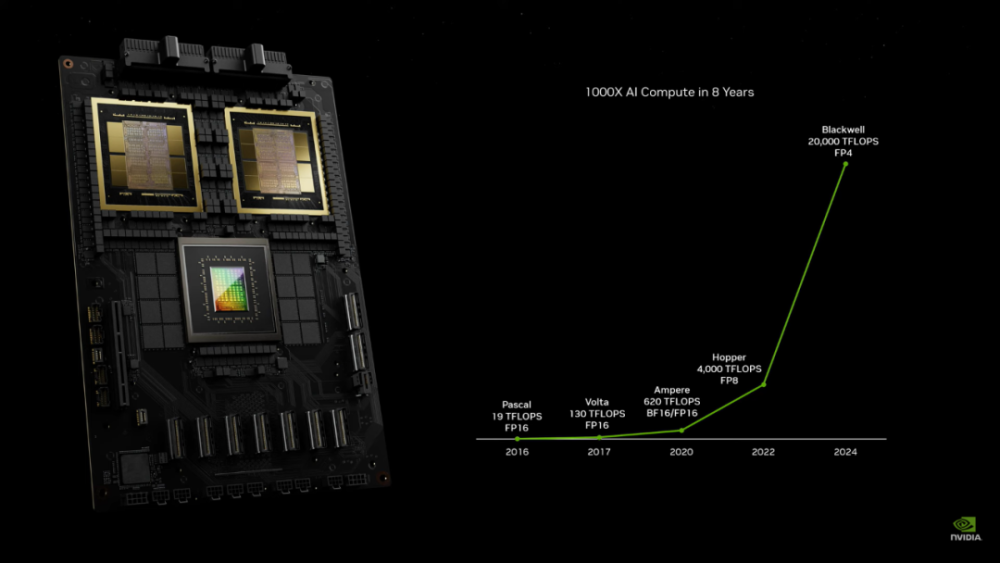
在展示BlackWell的后半段,老黄还回顾了从2016年开始,英伟达显卡在计算速度上的提升,虽然精度略有不同,但可以看出,这几年老黄在计算卡上确实没有挤牙膏,每次算力的提升都是实打实的。
02
超级计算机的新骨骼
除了芯片更强外,老黄在芯片互联之间也有大幅更新。
比如组成BlackWell的两个小芯片,它们之间的互联速度就达到了10TB/S,按照老黄的说法,这个速度已经可以满足芯片缓存(Cache)的要求,可以完全把它看作一个单独的大芯片。
英伟达引以为傲的NVlink,也算是这次最佳配角,全新的NVLink交换机带宽提升到了7.2TB/S。NVLink交换机的存在,就像人体的骨骼和血管一样,它的存在,把各个GPU计算节点连接在一起,让它们更好的发挥,协同。

这次NVLink的提升,72个的GPU可以连接在一起,组成一个DXG超级计算机,并且可以让整个计算机被看做一个超级大的GPU来用。
为了达到72个GPU之间的高速互联,DXG内部总共使用了3.2公里长的光纤线缆。

这样一台DXG服务器在训练AI时候的算力达到了恐怖的720 PFLOPs,6年前老黄亲手把DXG初代机交给马斯克和OpenAI的时候,那台机器的算力只有0.17 PFLOPs,6年时间,DXG服务器的算力提升了3600倍!

在介绍GPU的最后,老黄用大家熟悉的GPT做了一个非常量化的比较,他说目前的OpenAI最先进的模型的参数是1.8万亿个。
在使用A100 GPU训练的时候,需要25000个,耗费时间3-6个月,到上一代H100,数量降低到8000块,时间压缩到90天,需要消耗1500万度电,如果用最新的BlackWell GPU,训练时间没变,依然是90天,但是GPU的数量将缩减至1/4,电量只需要400万度。
03
老黄依然没有忘记元宇宙
2个小时的演讲中,前一个小时围绕着硬件,后一个小时则是软件的“推广”。
NIM是英伟达新推出的一种大模型部署“傻瓜化服务”,只要你的显卡支持CUDA,那么就可以非常简单的利用NIM来部署和微调出属于自己业务的大模型。
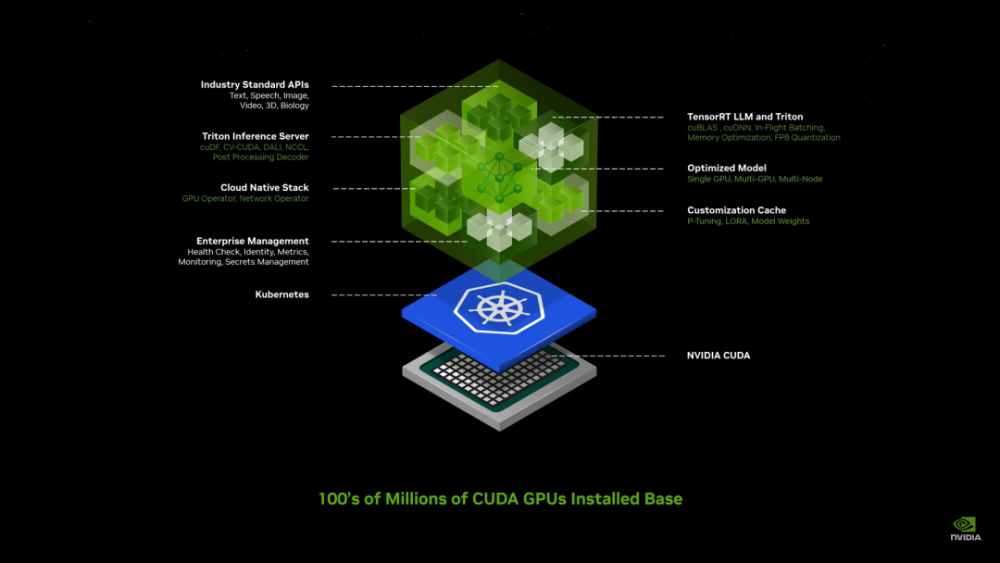
剩下的时间,老黄都在介绍它的“元宇宙”——Omniverse。只不过和以前单纯的把所有的东西都数字化不同,Omniverse现在更多的扮演了AI和现实世界中的中间层。
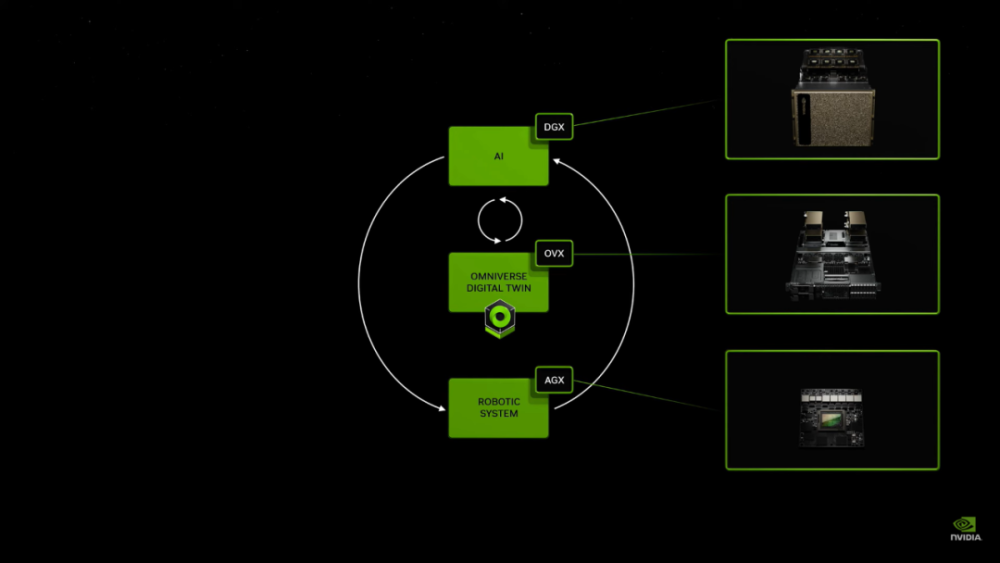
AI虽然能做到很多事情,但无法直接感觉现实世界,它只能通过各种资料来学习,从来没有实际上手过,就像经验值为0的小菜鸟。如果想让AI做到完美的控制机器,就要尽可能的让AI去现实世界中练习。
但现实练习的成本太高了,比如让AI管理一个仓库,总不能让工人,货物和机器人一起作AI的“陪练”。这个时候Omniverse就派上用场了,它对于现实物理的完美模拟,可以让AI在虚拟工厂中进行训练。
在老黄的例子中,Omniverse通过数字孪生把自动化工厂和工厂中搬运机器人联系起来。在工厂中,有一堆货物从货架上掉下来。
视频中AI会根据工厂中工人的位置,货物掉落的位置,为搬运机器人指出一条既不干扰工人工作,也不会被货物绊倒的路线。有过这样的经验,AI在现实中碰到同样的情况就可以妥善处理了。

在训练之后,人类还可以直接和AI对话,让它重现刚才发生的情况以及它的对策。
除了工业,老黄还启动了Gr00t计划,同上面一样,这也是一个AI,Omniverse,现实的三层结构。只不过这次它应用在机器人身上。
机器人通过AI,人类远程示教来进行学习,然后在Omniverse这个“虚拟锻炼场”进行各种锻炼,最终达到在现实中完成任务的目的。

演讲的最后,老黄还请出了一排机器人和两个装有英伟达Jetson处理器的小机器人,虽然和小机器人的沟通演示有些失败,但是对于一些像跟随,停止等基本指令,小机器人还是执行到位了。

04
人类已经处在AI发展的快车道上
简单总结下老黄的这次演讲,有两大重点。
第一,当然是AI算力的进一步提升,基于你的不同应用场景,新一代的英伟达芯片将带来2.5倍到30倍不等的算力提升。
这意味着我们将看到更强大的模型,以及更快的模型响应速度,具备实用性的视频图文语音多模态模型也将成为可能。这一块是英伟达市值翻倍的动力,也是接下来很长一段时间的中心所在。
第二,在大模型的应用场景上,老黄的目标,是从现在的白领服务业领域,向数字孪生,向工业,向机器人的方向扩展。
2024年我们将看到AI更多的出现在现实世界,特别是人型机器人的时代可能很快就会到来。
这确实是个让人害怕又兴奋的大时代。
总的来说,英伟达作为全球最炙手可热的科技公司之一,其持续不断的研发和发展推动着人工智能的发展。尤其是在AI革命的发生背景下,英伟达也在芯片性能和AI算力上进行了大量的投入和创新。
尽管如此,面对未来的挑战和竞争,英伟达仍然保持乐观的态度,认为随着技术的进步,新的AI模型将能够提供更快、更准确的服务,为更多的人类工作和生活带来便利。同时,老黄还在积极拓展Omniverse这个AI基础设施,使AI能够在现实世界中更好地服务于人类社会。
在未来,我们可以期待看到更多的AI应用出现在我们的生活中,包括但不限于智能家居、自动驾驶、医疗诊断、金融风控等领域。而在这个过程中,我们也需要注意保护个人隐私,避免AI技术滥用带来的风险。
总的来说,英伟达以其技术创新和对AI市场的深度理解,继续引领全球科技的发展趋势。而随着人工智能的普及和深入,我们也将迎来更加智能和便捷的生活方式。