文|武静静
|邓咏仪
炮轰OpenAI闭源,甚至与OpenAI对簿公堂的马斯克,说到做到,真的把自家的Grok开源了。
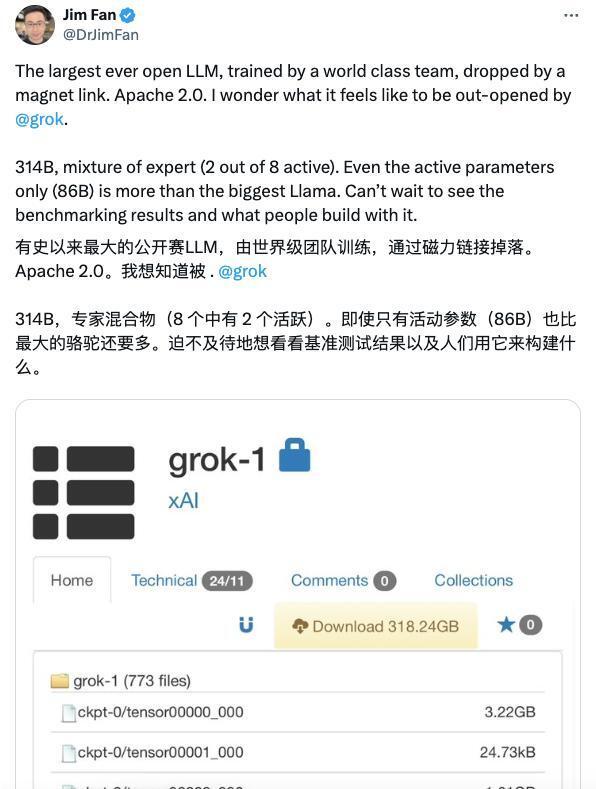
经历了一周的造势,当地时间3月17日,Grok-1开源版本如约而至。从参数来看,Grok-1是目前参数量最大的开源大语言大模型之一,其参数规模达到了3140亿,超过GPT-3.5当时1750亿的参数量。

图片来自Grok博客
目前Grok没有语言之外的其他能力,但xAI称,计划未来将Grok打造成多模态的大模型。
从ChatGPT发布后,马斯克就站在OpenAI对立面,成为排头兵,xAI也是为此而成立。不少人对Grok-1报以期待,想迫不及待试试。
截图自社交媒体平台X
好于GPT-3.5可商用,但难以迭代
xAI是马斯克2023年创立的大模型公司,其设计初衷是模仿科幻小说《银河系漫游指南》,提供尖锐的回复。目前Grok技术已集成到社交媒体平台X中,可以根据用户的帖子进行回复,订阅 X 高级功能的用户可以直接向Grok提问。
从整体测试效果来看,这次开源的Grok-1可以说“比上不足,比下有余”——在各个测试集中呈现的效果要比GPT-3.5、70b的LLAMA2和Inflection-1要好,但距离Claude2和GPT-4仍然差了一大截。
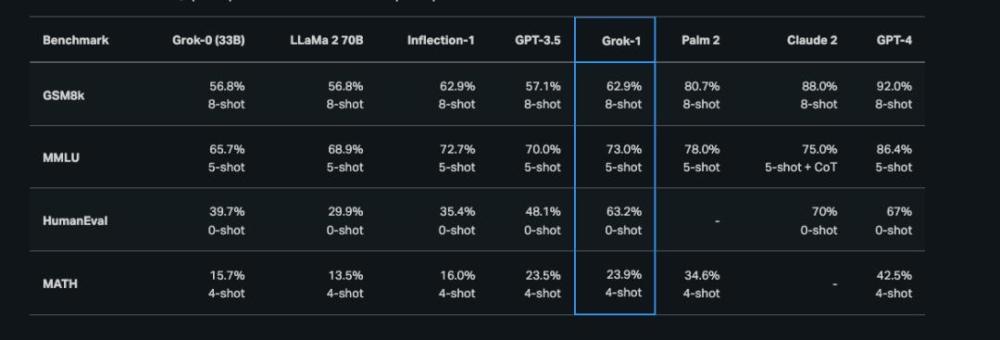
图片来自Grok博客
不过,由于Grok-1是xAI从零开始训练,在2023年10月就已经结束了预训练,且没有针对任何特定应用(如对话)进行微调,所以目前无法直接体验到对话的应用。
在社交媒体上,有人评论称,Grok-1没有对特定任务进行微调,提高了用户使用它的门槛,“市场需要特定的工具,而不是通用的人工智能。”
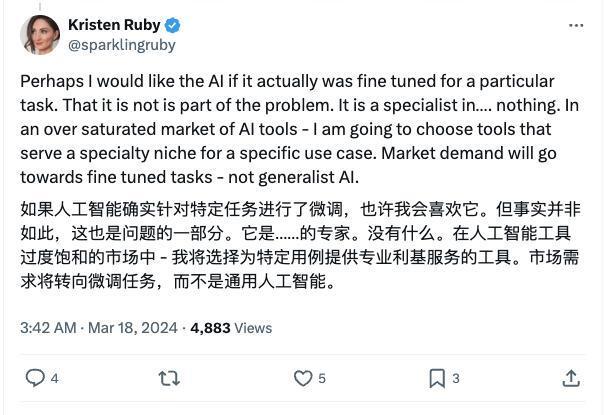
截图自社交媒体平台X
也有人认为,Grok-1这种方式可以适应多种不同的任务和应用场景,更适合那些想要用开源模型打造自己专有模型的开发者。
技术架构上,和GPT-4一样,Grok-1采用了大规模参数的专家混合模型(Mixture-of-Experts, MoE)架构,可以将大型网络分解为多个“专家”子模块,每个子模块负责处理不同类型的信息或任务。
底层技术上,Grok-1选择使用了基于JAX(一个由Google开发的用于高性能机器学习研究的库)和Rust(一种注重安全性和并发的系统编程语言)的自定义训练堆栈。
这并不是大型语言模型中常见的选择。大多数知名的大模型比如OpenAI的GPT系列或Google的大模型通常是基于TensorFlow或PyTorch这样的主流深度学习框架开发的,且有丰富的API和社区支持,能让模型开发和训练变得更高效。
但Grok-1将JAX和Rust的结合,优势在于能够在模型性能、效率和可伸缩性方面有所优化。但这也意味着,xAI可能需要投入更多的资源来维护和支持这种非主流的技术栈。
效率上,Grok-1模型也找到了更高效训练的方法。在Grok-1模型中,只有大约25%的权重在任何给定时刻是”活跃”的,可以把“权重”理解为参与信息处理的“工具”,这种“活性权重”可以减少不必要的计算,提高处理速度,同时也减少了冗余。
此外,Grok-1的权重和架构是在宽松的Apache 2.0许可下发布的,这使得研究者和开发者可以自由地使用、修改和分发模型,打开了更多开放合作和创新的可能性。
眼下,Grok-1面临的最迫切问题是模型参数太大(3140亿),这需要巨大的计算资源,所以开源社区无法对Grok-1进行迭代。
不过,目前,对话搜索引擎公司Perplexity CEO Aravind Srinivas已经在社交媒体上发文称,将会基于Grok的基础模型,进行对话式搜索和推理的微调。
截图自社交媒体平台X
OpenAI对立面:不断壮大的开源力量
Grok-1的开源也意味着马斯克已经选边站,站在开源这一头,身体力行的参与对抗OpenAI。

截图自社交媒体平台X
也有人认为,这是马斯克搞的又一次营销噱头。“一家营利性公司开源的东西往往表明它还不够好。”

截图自社交媒体平台X
但不论动机如何,马斯克此次确实给开源力量增加了有分量的筹码。
一直以来,开源和闭源的争议从未停止。市场争议主要集中在两端,OpenAI认为闭源能够让技术更安全的被使用,避免技术滥用;开源一方则认为技术不应该掌握在某家公司手中,需要更透明、更公开。几天前,苹果发布的多模态大模型MM1,也提到要致力于让技术更透明化。
用更直白的话来说,面对一骑绝尘的的OpenAI,模型层闭源的意义可能并不大,不如开放给社区一起迭代。因此,开源成为更多公司“团结起来”的选择。
一个典型例子是,Sora大火之后,中国创业公司潞晨科技团队就火速自研,推出了开源全球首个类Sora架构视频生成模型 「Open-Sora 1.0」,该模型包括整个训练流程,包括数据处理、所有训练细节和模型权重。
目前开源力量最大的参与方是Meta,也成为了AI开源社区中的“一面旗帜”,2023年7月,Meta发布了免费可商用版本大模型Llama 2。最近,已经有不少媒体报道称,Meta正在加紧开发新的大语言模型,预计在今年推出能力对标GPT-4的开源大模型。马克·扎克伯格此前还公开透露,会在2024年底前购买约35万张英伟达最先进的H100 AI GPU。
另一个有竞争力的公司是法国生成式AI独角兽Mistral AI,今年2月,Mistral AI发布全新旗舰模型Mistral Large。Mistral Large在基础测试中的表现出色,以81.2%的分数超越了谷歌Gemini Pro、GPT-3.5、Meta Llama 2-70B三款模型。成为仅次于GPT-4、世界第二大可通过API访问的AI大模型。
更多公司正在加速参与到大模型开源中,试图瓦解OpenAI闭源路线构建起的技术围墙。

欢迎来聊~
经过一周的造势,开源大语言大模型Grok-1终于如约而至。虽然没有语言之外的能力,但xAI对其表示了极大的期待,希望尽快试用。目前,Grok-1的最大特点是参数量高达3140亿,超过GPT-3.5当时1750亿的参数量。
然而,由于Grok-1的参数量过大,目前还不具备实现对话应用的能力。此外,考虑到模型性能、效率和可伸缩性的优化问题,xAI需要投入更多的资源来维护和支持这种非主流的技术栈。
尽管如此,Grok-1仍然是开源社区的一大力量,吸引了马斯克等科技巨头的关注。他的身影无疑是对开源力量的一次重要推动。
在未来,开源的力量将继续壮大,尤其是在大型语言模型领域。随着技术的发展和AI应用的不断扩大,越来越多的企业和个人都将加入到AI开源的大军中,共同构建更安全、更透明的AI环境。在这个过程中,开源不仅提供了模型的解决方案,也为科研人员提供了强大的工具和平台,让他们能够更好地探索和创新。