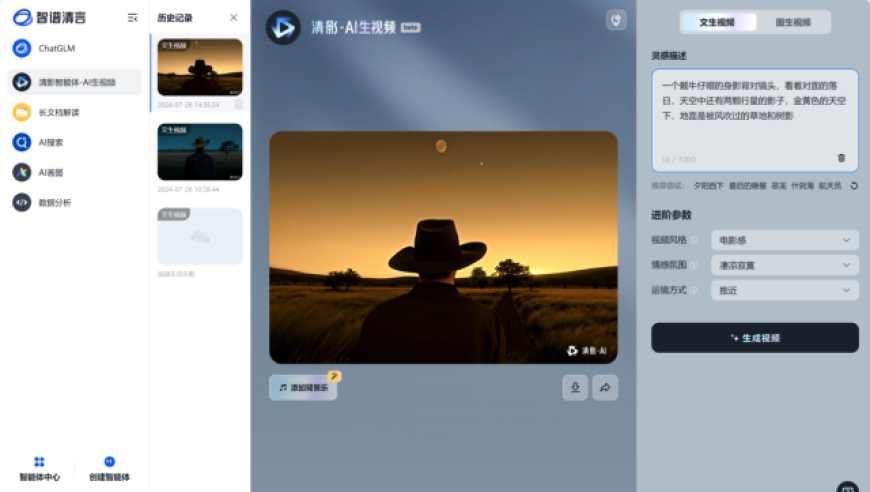
本文探讨了人工智能视频生成领域的快速发展,尤其是Sora发布以来,AI生成视频模型受到广泛关注。文中指出,这得益于庞大的视频数据集和高效的计算能力,但也存在一些缺点,如处理有限帧数的视频输入以及缺乏时间建模设计。为此,苹果公司提出了一种名为“SlowFast-LLaVA”的新模型,该模型结合了字节团队的LLaVA-NeXT架构,无需额外微调即可使用。研究表明,这种模型能够有效解决当前视频生成领域存在的问题,并在未来可能成为主流。相关链接可以在此处找到:
随着科技的进步和大数据的普及,AI技术在许多领域的应用越来越广泛,其中就包括视频生成。近年来,人工智能视频生成领域的快速发展引起了人们的关注,特别是Sora发布以来,AI生成视频模型受到广泛关注。
一方面,强大的视频数据集是AI生成视频的基础。如果没有大量的高质量视频数据作为训练样本,AI模型就无法产生出准确的视频。此外,高效的计算能力也是保证AI生成视频质量的重要因素。AI模型需要进行复杂的计算才能生成出逼真的视频画面,这就需要强大的计算资源来支撑。
另一方面,目前的AI生成视频模型还存在一些缺点,如处理有限帧数的视频输入以及缺乏时间建模设计。例如,对于一些短时间段内的视频片段,AI模型往往难以生成出高质量的画面。另外,由于缺乏时间建模设计,AI模型在生成视频时可能会出现“卡顿”现象,影响用户体验。
针对这些问题,苹果公司提出了一个叫做“SlowFast-LLaVA”的新模型。这个模型结合了字节团队的LLaVA-NeXT架构,无需额外微调即可使用。这种新的模型不仅解决了当前视频生成领域存在的问题,而且还有可能在未来成为主流。
总体来看,AI生成视频是一种极具潜力的技术,它不仅可以应用于娱乐行业,还可以用于教育、医疗等众多领域。未来,随着科技的发展,我们有理由相信,AI生成视频将会发挥更大的作用,改变我们的生活。